理赔大数据是如何助力保司扩大健康险市场份额?
理赔大数据是如何助力保司扩大健康险市场份额?本文将目光聚焦在健康险行业的“不健康人群”蓝海市场,剖析背后因信息不对称导致的逆选择问题,指出风险中存在的大量机会,并从数学上理清保险行业盈利的本质逻辑,提出利用理赔大数据进行用户画像和模型训练的思路。
一、问题:保险公司如何挖掘不健康人群市场?
人类几乎从诞生开始就学着如何与疾病做斗争,他们发明了医学、宗教与之对抗,但至今还没有赢得这场战争——几乎没有人一辈子不生病。从数据上看,健康人群是占少数的。安信证券研究中心的调研数据表明,2016年全国健康人群只占10%,而真正需要健康险保障的亚健康人群和疾病人群各占了75%和15%,总共占据90%的份额。
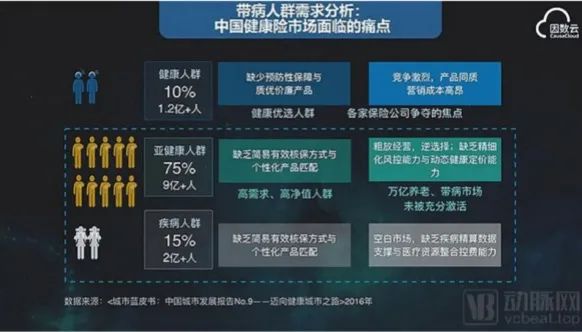
当然保险公司不会只保健康人群,监管会也有规定:保险公司对于短期健康险,每年都需要定期公布理赔率。如果保险公司的理赔率过低,客户会产生疑虑,监管会也会出手制裁。但是,根据中国保险行业协会发布的《2018中国商业健康保险发展指数报告》显示,目前国内购买商业健康险的居民仅占6.7%。可见,保险公司面对“不健康人群”会因数据支撑不够、数据分析不足,无法进行合理的判断,造成大量市场未被开发。
二、原因:信息不对称导致的逆选择(Anti-selection)问题
本质上,保险公司和投保人是一对矛盾体,双方会产生逆选择问题,即有病者要求参加健康保险,职业危险性大的人要求参加意外伤害保险,死亡率高的人要求参加死亡保险等。
面对有疾病史、住院史的客户,保险公司往往会非常谨慎,此时的核保决定可能是拒保、加费、除外或延期。“拒保”是因为客户患重大疾病且短期内不太可能恢复到健康状态;“加费”是根据客户身体情况,将其分类为特定人群,再根据特定人群的患病率增加保费;“除外”是不保客户投保前已患的疾病;延期则是等待一年或几年视客户身体情况而确实是否承保。
所以逆选择问题的根本是,保险公司因不能掌握更加全面的数据,无法对投保人进行科学、精准的评估,在规避风险的前提下,也就更加轻易地作出非承保决定。
三、解决思路:利用理赔大数据进行科学核保

深源恒际店铺主页链接:点击进入
首先,我们应该在风险中看到机会。如哲学家休谟所说:“道理都懂,但人只有经历过才能明白个中滋味。”对于健康人群,极力对其推销保险的重要性,花大量成本进行保险基础知识普及,作用并不大。但对于“不健康人群”,相比之下会更加轻易地赢得投保,因为他们领略着疾病的无情和不可控。
其次,保险行业盈利的模式为收益大于损失即可。保险的数学期望里,必然存在风险概率,所以一定会有赔付。下图是20家代表性企业公布的2020年度理赔数据,可以看到保险公司每年理赔的金额几乎都是以亿为单位。那么,如何实现收益大于损失才是问题的关键,如何把盘子做大更为重要,多了投保数量,结果就是放进一些涉及理赔的案件,同时也放进了带来收益的客户。如果风控做得不错,往往带来更大的收益。如此,整个博弈市场也会更加良性,消费者的权益得到保障,而保险公司也会
获得更好的口碑和更多的盈利。
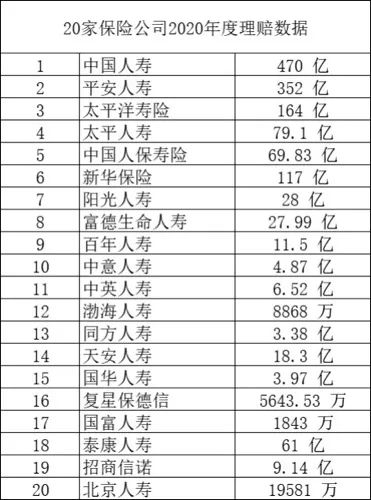
数据来源:公开资料整理
那么,在严控风险的情况下,如何挖掘冰山下面的蓝海市场?答案是对理赔大数据深度分析,最大限度挖掘客户信息,在了解客户风险的情况下,制定更加科学、精准的核保政策,精准扩大市场份额。保险公司对理赔大数据的分析可以按照以下4个方面进行:
①理赔大数据与移动互联网大数据结合可以精准扩大市场份额。随着移动互联网的发展,通过理赔大数据建立客户群的大数据库,在微信、微博等大量自媒体开展多样化的营销活动,实现平台化、社交化的营销服务模式,能借助线上数据和理赔大数据,实现更加精准的营销,在大数据的加持下规避了一定的风险,也扩大了市场份额。
②理赔大数据可以将客户的标签体系化,更好地了解客户的风险。通过对理赔大数据的聚类分析,保险公司可以把客户进行相似度计算,归类成成千上万种,例如,从风险上分类:将客户理赔数据划分上百种风险等级,不同等级对应不同的保费;从职业上分类:将不同职业下的人群进行聚类,形成各精细化的职业分类体系,将风险相似的职业归到一类,还可以从经济水平、年龄、过往病史等方面进行划分等等。有助于在保险的销售环节,注重对细分人群进行销售,在大数据的支持下,对不同的客户销售不同的保险产品,避免客户对产品产生抵触情绪,也能更好地了解客户投保的风险,做到精准销售而不是盲目销售。
③核保环节通过理赔大数据分析更可能发现理赔欺诈的线索,堵住风险漏洞。传统的核赔过程中,主要靠核赔人员的经验甄别风险,靠调查人员有意识的排查堵住理赔欺诈的发生。这种情况下,人为制造保险事故、虚报并不真实存在的保险事故、夸大保险事故损失金额,都成为可能发生的情况。但在大数据条件下,保险公司不同地区的既往理赔数据,甚至不同保险公司之间的理赔数据有可能汇聚成一个超级数据库。任何理赔申请,都可以先经过数据库的检验。
④理赔大数据可以形成科学的核保模型,控制风险。对从纯理论角度和最理想化的角度来讲,核保和核赔这两个环节是可以为保险公司屏蔽所有逆选择和道德风险,但付出的代价是用大量的人力对每个投保和理赔申请都进行大量的细致调查。这在保险公司实际运营中是不可能的。特别是在行业竞争越来越激烈的今天,为提升客户体验,保险公司的投保条件愈发宽松,核保核赔速度快,甚至免核保、免体检、快速赔付已经成为保险公司吸引客户的“标配”所在。各家公司千方百计提高服务速度,核保核赔部门往往要承受客户和销售部门的双重压力。在此情况下,虽然保险公司的保费收入有了较大增长,但是承受的风险冲击将明显增大。那么利用理赔大数据对投保人构建精准的用户画像,通过无监督以及有监督的机器学习算法进行训练,形成核保模型,便可以得出科学的核保政策,实现自动化的快速核保流程。
四、解决方案:深源恒际助力理赔大数据,实现投保人和保险人的双赢
深源恒际在健康险理赔场景下,深耕理赔全流程,以理赔大数据为抓手,利用海量数据训练模型,输出高精尖的机器识别算法,打造端到端的智能理赔产品,沉淀大量结构化理赔数据,支撑健康险保险公司进行大数据挖掘,建立全新的、科学的投保标准,高效判断准受保人资格,在严格把控风险的情况下扩大市场销售额。
通过深源恒际精心打造的“三步法”智能化理赔解决方案,AI Camera(智慧相机)、AI Classify(智能分类)、AI OCR(智能识别),可以快速实现理赔材料的线上化、结构化、数据化。深源恒际在沉淀理赔大数据中展现了如下独特性及差异性优势:
①可提供大量、全面的理赔数据:第一,机器识别替代传统人工录入,只需人工稍微辅助作业,便可确保理赔人的重要信息不被遗漏;第二,深源恒际的机器识别模型可沉淀详实、精细的数据,包括了被保险人信息,诊疗记录,医疗信息,赔付金额,疾病信息,药品信息等重要数据,可沉淀数据字段达80种,处于业内领先水平;第三,深源恒际将进一步扩大识别的文档类型,360度无死角支撑业务分析,形成当之无愧的大数据、巨数据。
②可提供结构化好的理赔数据:市面上现有的OCR机器识别软件,往往只能做到通用的文本识别,识别结果需要经过大量的手动纠正处理才能得到可使用的数据,而深源恒际是通过深度学习+模板化+自然语言处理技术,可以做到一键输出高精准的结构化数据以及校验结果,非常便捷。

③可不断迭代提供更加精确的数据:目前业内的深度学习模型准确率很难达到100%。针对这点,深源恒际研发了人工辅助机器的模式,可以在机器识别错误的情况下,人工进行辅助核验,引导模型自我迭代,升级为更加强大的工具。