Gluster集群管理小分析
开源分布式文件系统GlusterFS的集群管理系统GlusterD设计复杂,然而剖析其内部原理的参考文献极少,如果不熟悉源码,遇到问题解决难度比较大。本文的小目标是对GlusterD进行架构设计及代码层面的简析,深入了解GlusterD机制,从而帮助技术人员提高定位和解决问题的效率。
1 GlusterD架构设计
GlusterD作为GlusterFS的集群管理系统,其主要负责GlusterFS的集群信息管理,弹性卷管理,保证集群配置一致性,命令行操作,服务进程管理等。
GlusterD部署于每一个存储节点上,用于管理本地的服务进程状态,并与其他节点的GlusterD进程通信,保证集群信息一致。需要特别指出的是,GlusterD是完全无中心化的架构模式。所有GlusterD都是完全对等的。
其架构图如下所示:
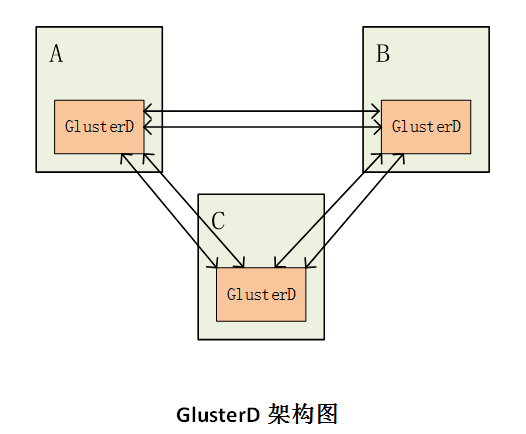
如图所示,GlusterD架构是完全无中心化的架构模式。所以其系统任意掉线(n-1)/2 个节点仍然可以对外提供服务。
GlusterD工作原理
那么在这种架构下,GlusterD是如何实现其管理功能,并保证集群数据一致性的呢?
以向存储池中添加节点为例进行分析:
如GlusterD架构图所示,现在已有A,B,C三个节点组建的集群,若要向该集群中添加节点D。则需在集群中原有任意一个节点(例如在节点A)上执行gluster peer probe D。
当执行完该命令后,该命令行会发送到本地的GlusterD服务上面,本地GlusterD服务判断D节点是否已经处于集群之中,还要通过D节点的GlusterD服务判断D节点是否处于其他集群之中。若不存在冲突,则将该节点添加到本地GlusterD的集群信息中。
此时节点A的GlusterD已经完成节点D的添加,然后会与B,C节点的GlusterD进行通信,并告知有新节点D加入集群,节点B,C的GlusterD收到A节点GlusterD的通知后,会主动探测D节点的GlsuterD,若链接正常,且不存在信息冲突,则将D节点加入到其本地GlusterD的的集群信息中。
在节点A向B,C发送添加节点D信息时,节点A也会把本地GlusterD中保存的集群信息同步给节点D。让D获得集群中所有的节点信息,并尝试与其建立链接。
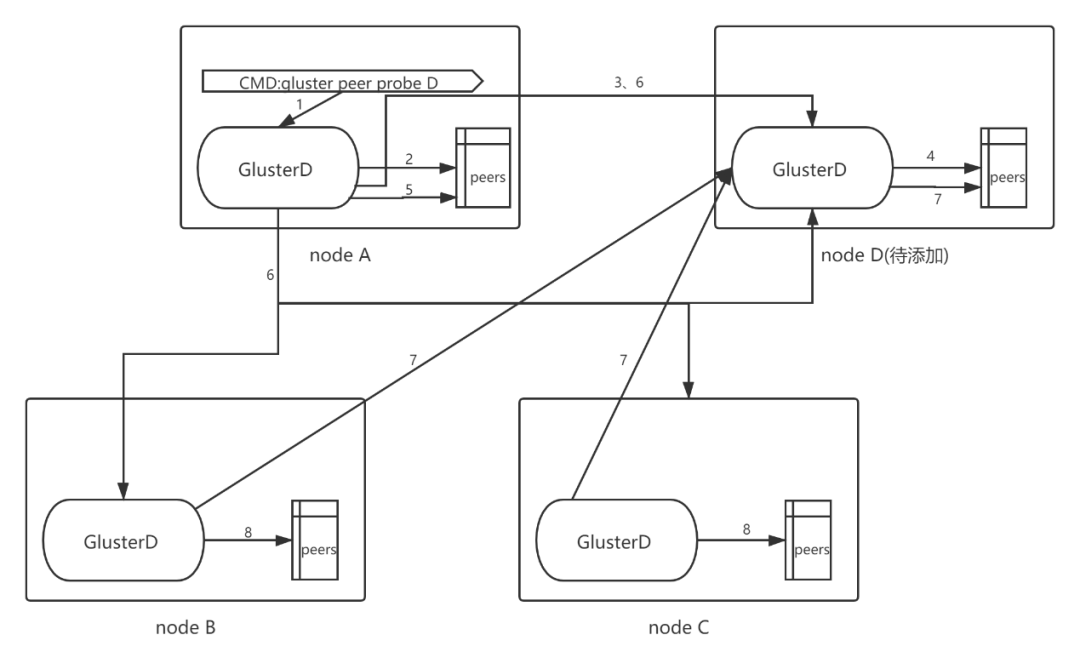
上图为添加nodeD过程图,序号相同代表同时发生
这样才完成了,一次集群新增节点操作。
在上述步骤中,当A节点添加成功后,同步其他节点的过程中,任何一个节点执行失败,都会造成集群信息不一致的情况。
可以看出,随着集群规模的扩大,A节点将会通知更多的节点执行探测新节点并加入集群的任务。这样将会对系统的一致性处理造成更大的挑战。复杂度也会随着节点数的增加而增加。
GlusterD架构优缺点
通过以上分析,可以看出GlusterD属于完全无中心化的,所有节点都属于全对等地位,这种设计方式,其优缺点都是十分明显的。
其优点在于:
1.无中心化设计方式,不会出现单点故障的问题。
2.操作灵活,可以在任意节点执行命令。
同时,其缺点是十分明显的:
1.维护节点间的状态关系,以及处理client命令的状态机都是相当复杂的。
2.如此复杂的逻辑,再加上多节点无中心化的设计,其故障率是比较高的。
3.出现问题时,难以定位。并且随着节点数的增加,其复杂度是指数级增加的。
2 GlusterD对比GlusterD2
为了优化GlusterD,GlusterFS官方社区对其做了优化,重新设计了新的管理系统GlusterD2,它是完全不同于GlusterD的全新的架构模式。放弃了原先的无中心化的设计思想,采用ETCD来做有中心化的设计。具有更好的伸缩性,且更加容易维护与管理。
GlusterD2的原理架构图如下:
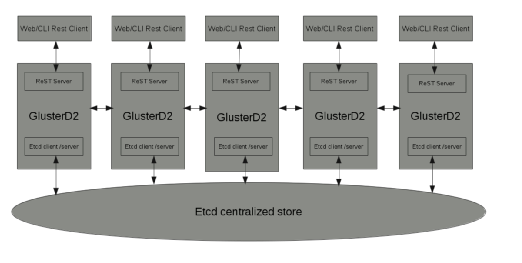
△GlusterD2架构图
从图中,可以看出,GlusterD2所有节点都是通过最下方的ETCD来同步信息,从而解决一致性问题的。这明显有别于GlusterD架构图的全对等模式。
架构设计对比
对比GlusterD可以看出,当客户端下发命令时,都是由GlusterD/GlusterD2接收并解析处理指令的。而不同的地方在于, 集群节点之间的信息不再是通过维护GlusterD之间的状态关系去维护,而是通过ETCD作为中心数据库去保持一致性。这样在设计与实现上,极大的简便了GlsuterD2的逻辑。
在设计上,GlusterD的配置信息和本地状态管理需要在所有节点上进行复制,当集群规模过大时,如上千和节点。就会出现特别难于管理的问题。而GlusterD2采用Etcd作为中心化管理,不再需要在所有节点上都维护配置信息和状态信息,只需要将此类信息存放在etcd上面,通过etcd去保证一致性问题。从而解决了扩展性的问题。
代码设计上的区别
在代码维护上面,原来的GlusterD方式每增加一个xlator都需要对GlusterD的核心代码进行修改,且完全采用C语言进行实现,这对GlusterD的代码管理及维护带来了很高的成本。
而GlusterD2在代码上面也做了重新的设计,并采用了go语言进行实现。其增加xlator的方式更加简单,且不会对GlusterD2的核心代码进行修改。以下是社区的原文描述:

3 GlusterD代码实现
通过以上分析,我们大致可以知道GlsuterD的难点在于其无中心化的设计思想,当有命令操作或者状态变化时,需要将操作同步到所有GlusterD节点上面,从而导致其在同步过程中,中间状态过多,出错几率较大。所以我们就更需要对GlusterD现有机制进行分析,了解其内部机制,以更加快速的定位与解决问题。
鉴于GlusterD内部逻辑细节较多且繁琐,不是一时能够完全梳理清楚的,本文主要从glusterd处理peer之间的状态,以及接受client命令之后glusterd之间的处理状态机进行分析。
在处理peer之间状态及glusterd任务协作时,主要通过处理保存于gd_firend_queue与gd_op_queue中的glusterd_friend_sm_event与glusterd_op_sm_evenet来实现。
下面将主要从glusterd进程初始化,op状态机处理,peer间状态三个方面进行阐述。
GlusterD初始化
在glusterd进程启动时,预先创建好rpc的监听服务以及glusterd_friend_sm和glusterd_op_sm两个队列,分别用于保存peer间状态以及操作的事件。其简略流程如下图所示:
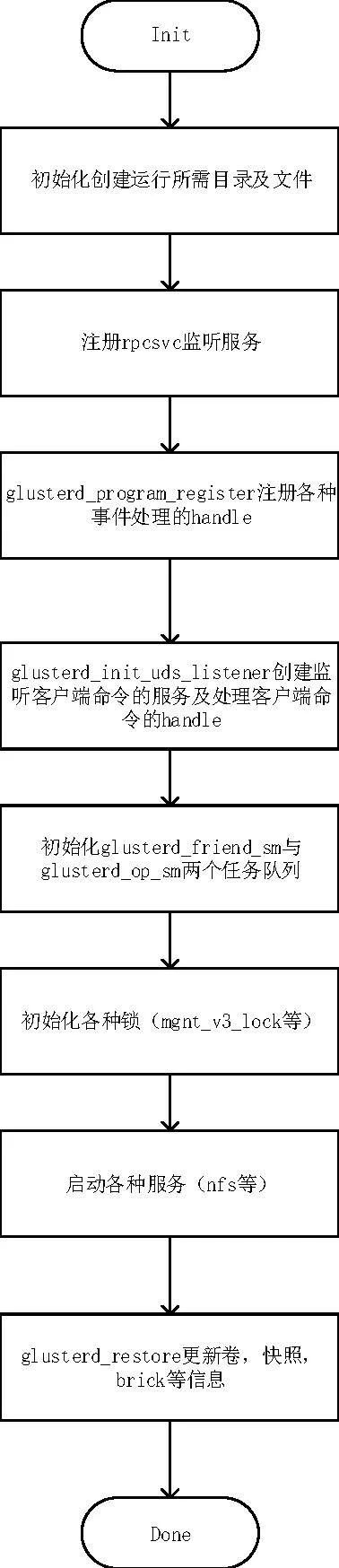
△Glusterd进程初始化流程图
如上图所示,在初始化过程可分为如下步骤:
1.分别创建了监听peer间的监听服务,用于接收peer间的状态处理事件。
2.glusterd_program_register创建了处理glusterd状态的句柄,如:gd_svc_peer_prog,gd_svc_mgmt_prog等。用于peer间friend关系的处理及op操作状态的处理。
3.glusterd_init_uds_listener用于创建监听客户端命令请求的服务,并注册处理客户端请求的句柄,如:gd_svc_cli_prog,用于接受并处理客户端发送来的命令请求。
4.glusterd_friend_sm及glusterd_op_sm初始化。初始化gd_friend_queue和gd_op_queue,分别用于保存peer间状态的事件以及op操作状态的事件。
5.其他信息初始化操作。
GlusterD接受client命令处理步骤
当glusterd守护进程接收到client的命令请求时,根据gd_svc_cli_prog注册的handle gd_svc_cli_actors[]来识别该命令,并进行相应的处理。
一般在处理相应请求时,是通过glusterd_handle_xxx函数进入处理流程的。
在glusterd_handle_xxx中一般是通过glusterd_op_begin_synctask()函数进入该命令在glusterd间状态机的流程当中的。
其流程如下图所示:
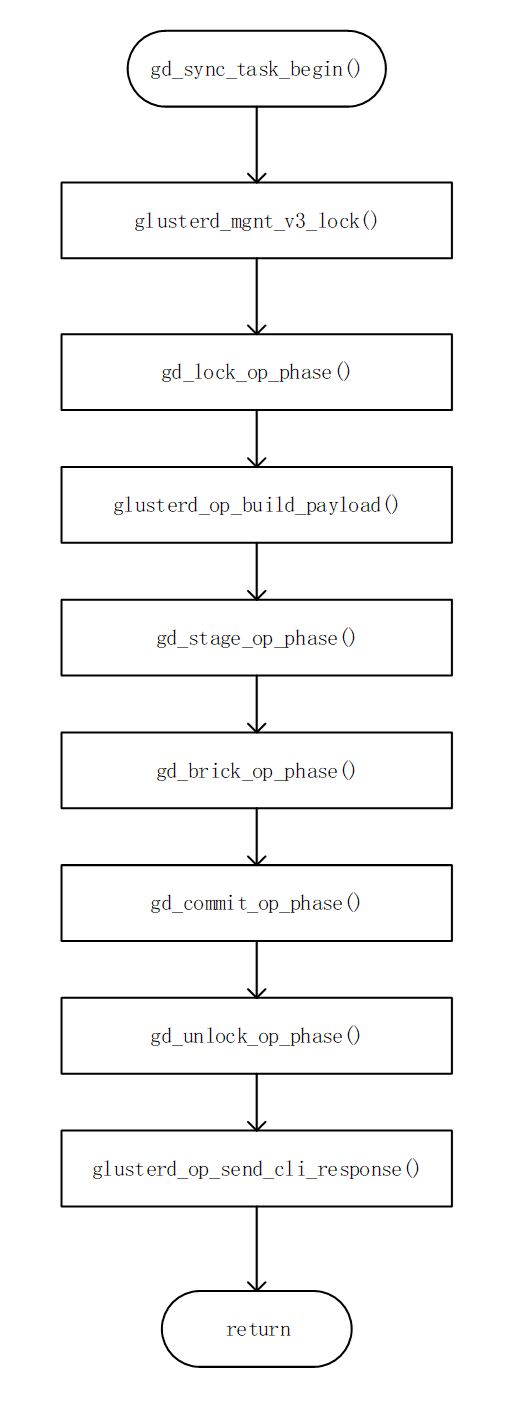
△Glusterd同步任务处理流程图
上述流程中每一个处理函数,都对应着一次glusterd处理任务的一个状态,每个状态对应着该状态的事件,及相应事件的处理方式。
此流程为发起节点向其他所有glusterd节点(包含自己)发送请求,并等待所有glusterd节点处理完成,且收到回复之后,才进入下一步。
而相应的,每个glusterd接受到相应的任务消息时,会通过gd_svc_mgmt_actots[]进入相应的glusterd_handle_xxx处理函数当中,在glusterd_handle_xxx处理函数当中,通过glusterd_op_sm_inject_event向gd_op_queue中注入相应的事件。
待完成事件注入之后,会进入glusterd_friend_sm()及glusterd_op_sm()函数,分别对gd_friend_queue和gd_op_queue中的事件进行处理。并进行相应的状态切换工作。
完成相应的事件处理之后,才会将处理完成的信息返回给发起节点。
GlusterD peer间状态
多节点GlusterD之间形成集群关系,主要在每一个glusterd进程中,都会记录该节点的所有friend节点的glusterd信息并记录与其他glusterd进程间的关系。所以,如何处理所有节点的friend关系,如何保证如此多节点friend关系的一致性问题,就成了glusterd逻辑的重要部分。
通过代码分析,其维护peer间状态关系的状态机及peer之间的事件类型可在glusterd-sm.h中查看:
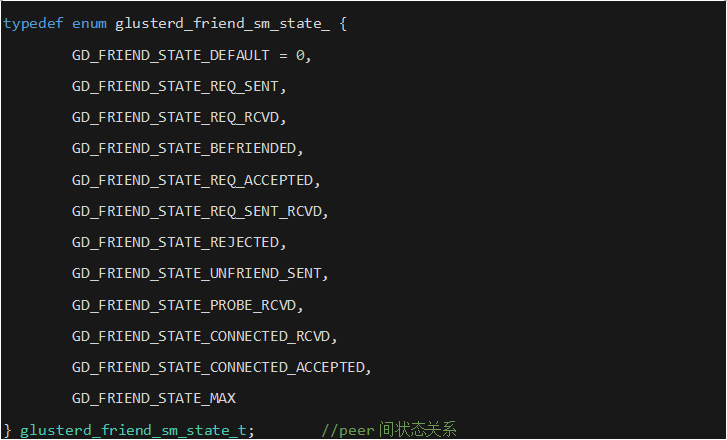
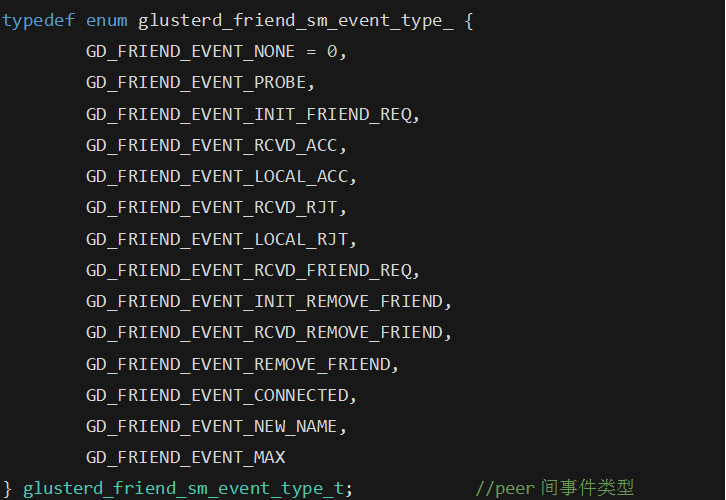
当有peer间事件发生时,通过glusterd_friend_sm()函数,可以从gd_friend_queue中取出事件,并根据当前节点的状态peerinfo->state.state获取处理事件的句柄handler=glusterd_friend_state_table[peerinfo->state.state][event_type].handler。
从该句柄即可进入当前事件的处理函数当中,进行相应的事件处理,并完成状态转换,注册下一个状态的事件。并通知glusterd_friend_sm()进行下一个状态的处理。如此进行,直到对应任务完成。
4 GlusterD常见问题处理
1)Peer rejectd state错误
该错误一般是因为被拒绝的节点的某些信息与其他节点不一致导致的。所以处理办法,一般都选择删除/var/lib/glusterd目录下除glusterd.info外的其他信息,然后自动同步的方法解决。步骤如下:
1) 停glusterd进程;
2) 进入/var/lib/glusterd目录,删除除了glusterd.info文件之外的其它全部内容;
3) 重新启动glusterd进程;
4) Probe一个正常运行的节点;
5) 再次重启glusterd进程,查看gluster peer status的状态;
6) 如果以上操作仍未能恢复故障节点,那么反复重启几次glusterd进程试试看,或者把全部步骤操作几次试试。
特别注意的是,在某些特殊情况下,即使采用以上方式同步,最后得到的信息还是不一致。这一般是因为某些卷的一些信息未能同步一直导致的。
可通过检查所有节点的/var/lib/glusterd/vols/vol-name/cksum是否相同,若相同则排除以上可能,若不同,则是因为/var/lib/glusterd/vols/vol-name/info信息未完全同步一致导致的。此时可以采用硬拷贝的方法,停掉glusted,然后将其他正常节点的/var/lib/glusterd/vols/vol-name/info拷贝到本节点,然后重启glusterd,即可恢复正常。
2)Glusterd无法启动
Glusterd无法启动原因比较多样,具体可查看日志报错,定位启动失败原因。但大多数情况下为以下几种情况:
1)依赖的服务未启动,如rpcbind。
2)端口被占用。
3)brick进程无法启动导致卷启动失败,从而无法启动glusterd。
3)集群gluster pool list显示不一致
该种情况大多数为增删glusterd节点过程中出现重启,导致glusterd信息在某些节点上未完全同步。
一般这种情况,只能通过人工找出最全的peer信息的节点,然后将/var/lib/glusterd/peers下面的所有文件同步到其他节点,然后重启glusterd。即可解决gluster pool list不一致的问题。
4)Glusterd无法正常提供服务
1)检查网络,防火墙,/etc/hosts等网络信息,排除网络信息导致的glusterd异常。
2)具体情况具体分析。
(TaoCloud团队原创)
本文转载自博主原创文章,原文链接:https://blog.csdn.net/liuaigui/article/details/108427870